

RDD Architecture
아래 내용을 기준으로 학습했습니다.
- 어떻게 RDDs를 생성하는지에 대해서 이해
- RDD의 performance를 증가시키기 위해 partitions을 관리
- RDD resilient를 만들게 하는게 무엇인지
- RDDs가 jobs, stages에서 broken이 되었을때 어떻게 처리하는지
- Serialize tasks
RDD Review
RDD에 대해서는 이전에도 언급한바가 있기 때문에 간단하게 언급하면, Spark = RDD라고 생각하면 된다. 그 만큼 RDD는 Spark를 이해하는데 있어 가장 중요한 요소라고 할 수 있습니다. RDD는 여러개의 파티션들로 구성이 되어있고, 파티션의 개수는 Spark에서 클러스터의 CPU의 코어의 개수를 기반으로 결정이 됩니다. 여기서 언급하는 파티션은 spark의 parallel 실행의 성능을 좌우하는 중요한 역할을 합니다. 아래 글을 통해 파티션의 중요성을 알아보도록 하겠습니다.
어떻게 RDDs를 생성하는지에 대해서 이해
Spark에서는 입력을 위해 Hadoop APIs를 사용하기 때문에 HDFS, local file system, cloud service (Cloudant, AWS, Google, Azure)에서 데이터를 읽을 수 수 있습니다. hadoopFile API를 사용해 HBase, MongoDB, Cassandara 등을 직접적으로 읽을 수 있다. 필요하다면 custom InputFormats를 구현을 할 수도 있습니다.
파티셔닝에 고려해야할 사항들
파티셔닝을 잘 해야 태스크를 효율적으로 처리가 가능합니다. 파티셔닝은 앞서 언급한바와 같이 spark의 성능에 중요한 요소입니다. 파티션의 개수는 클러스터의 CPU의 코어의 개수에 따라 결정이 되고, 파티션을 효율적으로 하게 되면 parallelism을 증가시키고, Worker 노드의 bottleneck의 위험을 줄일 수 있습니다. 또한 Worker노드 사이에 데이터 이동이 줄어들기 때문에 shuffling의 코스트도 절약을 할 수 있습니다. 또한 shuffling은 OOM(Out Of Memory)의 위험이 있기 때문에 최소한으로 동작하게끔 하는게 중요합니다.

파티션을 어떻게 효율적으로 나누면 되는지에 대한 예를들어보면 현재 나의 클러스터 환경은 코어의 개수가 3개이고, 4개의 파티션을 만들었습니다. 우리가 처리해야 하는 record는 1000개가 있고, 이 1000개를 처리하는게 하나의 task라고 생각했을때 소요되는 시간이 1시간입니다. 이런 환경에서 task를 처리하면 2시간의 시간이 소요하게 됩니다. 3개의 코어는 각각의 파티션을 처리하고, 한개 남은 파티션은 하나의 task를 완료한 코어에 의해 처리가 될 것입니다. 이렇게 처리하게 되면 나머지 2개의 코어는 1시간동안 1개의 코어가 하나의 task를 처리하는 시간 동안 아무런 처리를 하지 않게 됩니다.
그렇다면 파티션의 개수를 3개로 한다면 어떻게 될까요. 각 파티션이 처리해야 하는 task는 3개이고, 각 task는 1300개의 records를 처리해야 합니다. 기존에 1000개를 처리하는 것보다 처리해야하는 양이 많아지지만, 한번에 각 코어가 각 파티션을 처리가 가능하기 때문에 약 80분이면 모든 작업이 완료됩니다.
즉, 파티션의 개수는 spark에서 성능을 향상시키는데 중요한 요소입니다. 2시간의 작업을 할 것인가. 파티셔닝을 잘해서 80분에 작업을 마칠것인가. 개발자의 역량입니다.
Factors to partitioning
기본적으로 파티션과 records는 기존 스토리지 시스템의 InputFormat을 기반하여ㅂ 분배가 됩니다. 예를들어 Hadoop의 partitions에서는 HDFS의 cores의 개수에 따라 결정이 납니다.파티션의 개수를 줄이거나, 늘리는 작업은 Repartition과 Coalesce로 가능합니다.
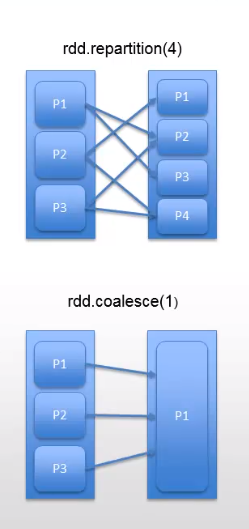
- Repartition은 filtering이나 records의 개수가 줄어든 이후에 전체를 rebalance를 해 파티션을 균등하게 재 분배하는데 도움을 줍니다. 이렇게 repartition을 하고 나면 parallelism이 증가하게 됩니다. 하지만 shuffling이 발생하게 됩니다.
- Coalesce는 shuffle을 발생하지 않고, 파티션을 통합(consolidate)하여 파티션의 개수를 감소시키는 역할을 합니다. 파티션의 개수가 줄어들기 때문에 parallelism은 감소하게 됩니다. 용도는 HDFS, 외부시스템으로 데이터를 저장하기전에 사용합니다.
Partitioners for key/value RDDs
map, keyBy를 통해 RDD를 생성할때, 파티션을 변경하지 않습니다. 결과적으로 생성된 key-value의 RDD는 최초 생성될때 partitioner를 가지고 있지 않기 때문에 같은 위치에 있는지 없는지 알수가 없습니다. 이 말은 key-value의 RDD가 key와는 전혀 상관없이 각 파티션에 분포가 되어있기 때문에 key를 기반으로 하는 연산을 할 경우 많은 shuffling이 발생하게 되고, 성능 저하를 발생할 수 있습니다. 그렇다면 같은 key를 갖고 있는 records가 co-located되어 있다면, 반복적인 작업이나 key를 기반으로 하는 연산을 더 효율적으로 할 수가 있습니다. 이렇게 되면 같은 JVM에서 transformations을 빠르게 실행을 할 수가 있습니다.

HashPartitioner, RangePartitioner를 이용해 위와 같이 같은 key를 갖고 있는 records를 co-located 할 수 있습니다.
HashPartitioner경우에는 파티션의 개수를 미리 결정하고, 같은 해를 갖는 모든 key를 같은 파티션으로 배분을 합니다. partition = Key % numPartitions의 연산으로 key의 records의 위치가 결정이 됩니다. 이런 방식을 consistent hashing이라고 합니다. partitionBy를 호출하면 shuffle이 발생하지만, co-located records로 부터 downstream 연산을 효율적으로 할 수 있습니다.
partitionBy 예제
최초에 파티션이 3개 생성되어 있었고, 0개의 Partitioner의 환경에서의 RDD를 고려해보면, keys는 co-located가 아닙니다. 이 말은 각 key는 파티션에 규칙이 없이 분포하고 있습니다. key를 기반으로 하는 연산을 할 예정이라면 같은 key를 갖는 records를 같은 파티션에 위치하도록 재파티셔닝을 하는게 좋습니다. 간단하게 hash partitioner와 함께 partitionby의 함수를 호출하면, shuffle이 발생하고, 그 이후에는 key기반의 연산을 더 효율적으로 할 수 있습니다.
Join Partitioning
partitioner가 없이 만약에 두개의 RDD를 join하면, 하나의 RDD가 다른 Worker Node로 모든 값들을 shuffling을 해야한다. 이렇게 되면 효율적이지 못한 join을 하게 되는 것입니다. 만약 같은 RDD를 반복적으로 join을 하면 엄청나게 비효율적인 연산을 하게 됩니다.
만약 join을 하기 위한 두개의 RDD가 같은 파티션에 있다면 가장 좋은 시나리오라고 할 수 있습니다. 이렇게 되면 Network I/O와 latency를 최소화 할 수 있습니다.
Resilience
RDD는 두가지 연산인 transformation과 action을 지원합니다. spark는 기본적으로 lazy execution을 하기 때문에 transformations의 lineage를 RDD로 표현이 가능합니다. spark에서는 transformations의 기록을 DAG로 표현을 합니다.
왜 RDD의 lineage 변화 과정을 저장을 해놓을까요. Resilience의 뜻은 탄력성이라는 뜻을 갖고 있습니다. 아무래도 탄력적으로 무언가를.. 할 수 있나봅니다. lineage를 저장하는것은 객체를 저장하는 비용보다 저렴하기 때문에 효율적입니다. 예를 들어 A->B->C의 RDD의 변화를 저장해놓은다고 생각할때 모든 객체를 저장하기 보다는 A에서 B를 만드는 방법, B에서 C를 만드는 방법을 저장하는게 더 효율적이겠지요? 그렇습니다.
ineage를 저장하는 목적은 spark에서 실행 도중에 failure event의 결과를 받을 경우 spark는 lineage를 참고해 RDD를 reconstruct를 합니다. 그렇기 때문에 어느한 파티션이 실패가 발생해도, 해당 파티션에서만 persisted RDD, root RDD를 lineage tree를 이용해 재계산이 가능하게 됩니다.
Executing Jobs (job->stage->task)
spark에서는 실행이 어떻게 되는지 살펴보면, 우리가 최초 코딩을하게 되면 여러 단계의 transformations과 마지막 action을 하게 됩니다. 이렇게 filter, map의 transformation의 연산을 하게 됩니다. 이처럼 transformations의 sequence를 job이라고 말합니다. transformations으로 RDD lineage로 생성을 하게 되고, scheduler는 RDD lineage를 분석해서 job을 stage로 쪼갭니다. job을 쪼개는 기준, stage가 나뉘어지는 기준은 shuffle dependencies에 의해서 정해집니다. transformations에서 shuffle을 발생시키는 join, repartition의 연산은 stage가 나뉘어지는 기준이 될 수 있습니다.
tasks는 serialized되고, 각 worker노드의 executors로 분배가 됩니다. 여기서 serialization을 하는 이유는 netowrk를 통해 worker노드로 전달되기 때문입니다. 전달하기전에 serialization을 하고, 각 worker노드에서는 de-serialization을 하는 cost가 발생합니다.
Identifying Stages
앞서 언급한바와 같이, job을 break down할때는 stages는 shuffle dependencies에 의해서 정의가 됩니다. 하나의 예제를 통해서 stages가 어떻게 나뉘어 지는지에 대해서 살펴보겠습니다.
시나리오) 2개의 RDD를 join한뒤에 결과를 reduceByKey를 하고, 마지막으로, saveAsTextFile의 함수를 호출한다.

rdd.toDebugString()을 통해서 RDD lineage를 확인할 수 있습니다. keyBy, map, keyBy의 연산을 통해 기존 RDDs를 transformations 했습니다. 그 다음 두개의 RDD를 join을 하게 되는데, 이때 join에서는 shuffle이 발생하기 때문에, stages의 boundaries가 되고, 나머지 작업은 3번째 stages로 들어가 작업을 실행합니다.
Handling Straggers and Failures
Stragger의 뜻이 낙오자라고 하네요. 낙오자...와 실패한놈들을 어떻게 처리해야할지에 대한 설명입니다. spark에서는 천천히 작업이 되고 있는 tasks를 처리하는 것을 speculative execution이라고 부르고 있습니다. 천천히(?) 작업이 되고 있는 tasks의 경우에는 필수적으로 re-launch를 해야합니다.
speculative execution은 기본적으로 설정이 꺼져있습니다. 그렇기 때문에 실행을 하기 위해서는 spark.speculation의 파라미터값을 true로 변경을 해줘야 합니다. 그렇다면 느리다, 천천히라는 정도를 어떻게 구분할까요? 그것또한 spark.speculation.multiplier를 통해 설정을 하실 수 있습니다. 이 설정은 speculation의 중간값보다 몇배 더 느린지에 대한 정도를 설정할 수 있습니다. 중간이 3이라면 2를하면, 6이 넘으면 이 tasks는 느린 작업이라고 판단하고 re-launch를 할 것입니다.
Concurrent Jobs
Spark의 환경을 구축하고 여러 사람이 여러개의jobs을 동시에 제출하게 되면 어떻게 해야할지에 대한 설명입니다. Spark에서는 기본적으로 FIFO스케줄러를 사용을 합니다. FIFO 스케줄러는 한 사용자의 app을 잘 동작하게 해주는 역할을 하기 때문에 각 job은 자신이 필요로 하는 리소스의 양 만큼을 얻어 사용합니다. 여러개의 jobs이 동시에 제출(submit)이 된다면 parallel하게 동작이 되야 합니다. 하지만 첫번째 job은 클러스터의 모든 resources를 필요로 하지 않을 경우에는 parallel하게 동작을 하겠지만, 만약 큰 job이 들어올 경우에는 다른 job들은 이전 작업이 끝날때까지 대기를 해야합니다.
Zeppelin에서 많은 사용자가 작업을 하는 환경에서, spark.schedule.mode의 파라미터의 값을 조정해 Fair 스케줄러를 사용할 수 있습니다. 기본적으로 fair 스케줄러는 클러스터의 리소스를 동등하게 분배를 합니다. 결과적으로 큰 작업(리소스를 많이 사용하는)임에도 불구하고, 다른 유저로 부터 제출된 작은 작업을 멈추지않고 시작하고 실행합니다.
Fair스케줄러처럼 동등하게 자원을 분배하는 방식이 아닌, pool을 정의해 가중치나, 최소한의 클러스터 리소스를 공유하라는 정의를 할 수가 있습니다. 내가 공유를 하고자 하는 자원의 양을 XML에 정의하고, spark.scheduler.allocation.file에 함께 제출하시면 됩니다. 이로서 pool읜 자신만의 scheduler를 갖게 되었습니다.
[참고] Big Data University - Spark Fundamentals II
'Big Data > Apache Spark' 카테고리의 다른 글
| [Spark] RDD데이터 파티셔닝 - 이론 및 예제 (0) | 2021.05.06 |
|---|---|
| [Spark] RDD 영속화(캐싱) - 이론 및 예제 (0) | 2021.05.06 |
| [Spark] Caching and Serialization (0) | 2021.05.06 |
| [Spark] Optimizing Transformations and Actions (0) | 2021.05.06 |
| Spark RDD - Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing (0) | 2021.05.06 |
| Spark Shell을 이용한 간단한 예제 및 앱 배포 방법 (0) | 2021.05.06 |
| Spark - RDD (0) | 2021.05.06 |
| Spark 클러스터 구조 (0) | 2021.05.06 |