

데이터 분석 머신러닝 예제 - Loan Prediction
데이터 분석에 대해서 학습을 할때, 매번 이론만 보니까 크게 와닿은 감이 없었습니다. 몇개의 유명한 사이트에서는 데이터 분석 주제를 던지고, 분석가들 사이에 서로 경쟁을 하는 사이트가 있습니다. 상금도 걸려 있으니 한번 시간이 나면 해보는것도 좋은 경험이 될 것 같습니다. 그 외에도 사이트에서는 data science에 대해서 학습할 수 있는 글 이나 예제을 주니 학습하는데는 좋은 사이트입니다. 실제 데이터 분석가들이 작성한 글이기 때문에 많은 도움이 될것입니다. 주요 사이트는 아래와 같습니다.
http://datahack.analyticsvidhya.com/
이번에 접해본 예제는 Loan Prediction의 문제입니다. 데이터를 preprocessing하고, logistic regression, decision tree, random forest을 이용해 예측을 하였습니다.
아래 코드와 함께 주석으로 설명을 해놓았습니다.
In [2]:
# dataset 불러오기
import pandas as pd
import numpy as np
import matplotlib as plt
# jupyter에서 matplotlib의 결과를 아래 바로 보이게 하기 위해 %matplotlib inline을 입력합니다.
%matplotlib inline
# 다운로드 받은 데이터를 pandas의 dataframe형태로 읽어옵니다.
df = pd.read_csv("/home/cluster/Desktop/train_u6lujuX_CVtuZ9i.csv")Quick Data Exploration
In [3]:
# head(N)의 함수를 통해 데이터 top N을 출력을 할 수 있습니다.
df.head(10)Out[3]:
| Loan_ID | Gender | Married | Dependents | Education | Self_Employed | ApplicantIncome | CoapplicantIncome | LoanAmount | Loan_Amount_Term | Credit_History | Property_Area | Loan_Status | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | LP001002 | Male | No | 0 | Graduate | No | 5849 | 0.0 | NaN | 360.0 | 1.0 | Urban | Y |
| 1 | LP001003 | Male | Yes | 1 | Graduate | No | 4583 | 1508.0 | 128.0 | 360.0 | 1.0 | Rural | N |
| 2 | LP001005 | Male | Yes | 0 | Graduate | Yes | 3000 | 0.0 | 66.0 | 360.0 | 1.0 | Urban | Y |
| 3 | LP001006 | Male | Yes | 0 | Not Graduate | No | 2583 | 2358.0 | 120.0 | 360.0 | 1.0 | Urban | Y |
| 4 | LP001008 | Male | No | 0 | Graduate | No | 6000 | 0.0 | 141.0 | 360.0 | 1.0 | Urban | Y |
| 5 | LP001011 | Male | Yes | 2 | Graduate | Yes | 5417 | 4196.0 | 267.0 | 360.0 | 1.0 | Urban | Y |
| 6 | LP001013 | Male | Yes | 0 | Not Graduate | No | 2333 | 1516.0 | 95.0 | 360.0 | 1.0 | Urban | Y |
| 7 | LP001014 | Male | Yes | 3+ | Graduate | No | 3036 | 2504.0 | 158.0 | 360.0 | 0.0 | Semiurban | N |
| 8 | LP001018 | Male | Yes | 2 | Graduate | No | 4006 | 1526.0 | 168.0 | 360.0 | 1.0 | Urban | Y |
| 9 | LP001020 | Male | Yes | 1 | Graduate | No | 12841 | 10968.0 | 349.0 | 360.0 | 1.0 | Semiurban | N |
In [4]:
# numerical variables의 summary를 확인 할 수 있습니다.
# describe()는 count, mean, std, min, quartiles, 그리고 max의 값을 ouput으로 반환합니다.
df.describe()
# 여기서 우리가 추론(inferences)이 가능합니다.
# 1. LoanAmount의 count를 보면 다른 column의 count보다 개수가 부족한 것을 알 수 있습니다. 즉, (614-692) 22 missing value
# 2. Loan_Amount_Term, Credit_History의 값도 LoanAmount와 동일하게 missing values 발생
# 3. Credit_History의 경우 값(0,1)을 갖고 있기 때문에, 평균(84%)는 credit_history를 갖고 있다. 라고 말할 수 있음
# 4. ApplicationIncome의 distribution은 CoapplicantIncome과 유사한 형태를 보여주고 있다.
/usr/local/lib/python2.7/site-packages/numpy/lib/function_base.py:3823: RuntimeWarning: Invalid value encountered in percentile
RuntimeWarning)Out[4]:
| ApplicantIncome | CoapplicantIncome | LoanAmount | Loan_Amount_Term | Credit_History | |
|---|---|---|---|---|---|
| count | 614.000000 | 614.000000 | 592.000000 | 600.00000 | 564.000000 |
| mean | 5403.459283 | 1621.245798 | 146.412162 | 342.00000 | 0.842199 |
| std | 6109.041673 | 2926.248369 | 85.587325 | 65.12041 | 0.364878 |
| min | 150.000000 | 0.000000 | 9.000000 | 12.00000 | 0.000000 |
| 25% | 2877.500000 | 0.000000 | NaN | NaN | NaN |
| 50% | 3812.500000 | 1188.500000 | NaN | NaN | NaN |
| 75% | 5795.000000 | 2297.250000 | NaN | NaN | NaN |
| max | 81000.000000 | 41667.000000 | 700.000000 | 480.00000 | 1.000000 |
In [5]:
# non-numerical values에 대해서는 (e.g. Gender, Married, Education, Property_Area etc.)
df['Property_Area'].value_counts() Out[5]:
Semiurban 233
Urban 202
Rural 179
Name: Property_Area, dtype: int64Distribution analysis
In [6]:
# ApplicantIncome을 histogram으로 표현
df['CoapplicantIncome'].hist(bins=50)Out[6]:
<matplotlib.axes._subplots.AxesSubplot at 0x7fba53091950>

In [29]:
# ApplicantIncome의 분포를 확인하기 위해서 boxplot으로 표현하면 아래와 같습니다.
# 아래 차트를 보면 outliters/extreme values가 많은 것을 볼 수 있습니다. 즉, 사회에 income disparity가 있다.
df.boxplot(column='ApplicantIncome')
/usr/local/lib/python2.7/site-packages/ipykernel/__main__.py:3: FutureWarning:
The default value for 'return_type' will change to 'axes' in a future release.
To use the future behavior now, set return_type='axes'.
To keep the previous behavior and silence this warning, set return_type='dict'.
app.launch_new_instance()Out[29]:
{'boxes': [<matplotlib.lines.Line2D at 0x7f0b59740ed0>],
'caps': [<matplotlib.lines.Line2D at 0x7f0b5974fd50>,
<matplotlib.lines.Line2D at 0x7f0b5975a3d0>],
'fliers': [<matplotlib.lines.Line2D at 0x7f0b596e7090>],
'means': [],
'medians': [<matplotlib.lines.Line2D at 0x7f0b5975aa10>],
'whiskers': [<matplotlib.lines.Line2D at 0x7f0b5994a8d0>,
<matplotlib.lines.Line2D at 0x7f0b5974f710>]}
In [8]:
# 사회에 income disparity가 있다면 Education의 차이에 따라서 구분을 지면
# Graduate의 수입 mean이 Not Graduate보다 높은 것을 볼 수 있다. 또한 Graduate에서는 High incomes가 보이고, outlier로 나타난다.
df.boxplot(column='ApplicantIncome', by = 'Education')Out[8]:
<matplotlib.axes._subplots.AxesSubplot at 0x7ffc8e5e4250>

In [9]:
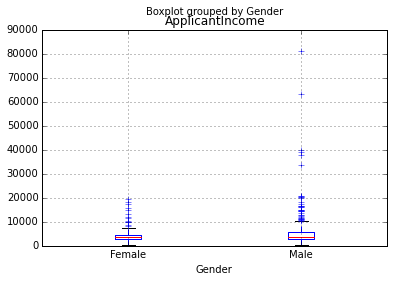
# Gender로 그룹을 나눈 상황은 아래와 같다. Male이 Female보다 high incomes가 많은 것을 볼 수 있음
df.boxplot(column='ApplicantIncome', by = 'Gender')Out[9]:
<matplotlib.axes._subplots.AxesSubplot at 0x7ffc8e38f6d0>
In [10]:
df['LoanAmount'].hist(bins=50)Out[10]:
<matplotlib.axes._subplots.AxesSubplot at 0x7ffc8e2921d0>

In [11]:
df.boxplot(column='LoanAmount')
/usr/local/lib/python2.7/site-packages/ipykernel/__main__.py:1: FutureWarning:
The default value for 'return_type' will change to 'axes' in a future release.
To use the future behavior now, set return_type='axes'.
To keep the previous behavior and silence this warning, set return_type='dict'.
if __name__ == '__main__':Out[11]:
{'boxes': [<matplotlib.lines.Line2D at 0x7ffc8e008f10>], 'caps': [<matplotlib.lines.Line2D at 0x7ffc8e015dd0>, <matplotlib.lines.Line2D at 0x7ffc8e021450>], 'fliers': [<matplotlib.lines.Line2D at 0x7ffc8e02a110>], 'means': [], 'medians': [<matplotlib.lines.Line2D at 0x7ffc8e021a90>], 'whiskers': [<matplotlib.lines.Line2D at 0x7ffc8e0151d0>, <matplotlib.lines.Line2D at 0x7ffc8e015790>]}

In [12]:
df.boxplot(column='LoanAmount', by='Gender')Out[12]:
<matplotlib.axes._subplots.AxesSubplot at 0x7ffc8e0ba590>

In [13]:
df.boxplot(column='LoanAmount', by='Education')Out[13]:
<matplotlib.axes._subplots.AxesSubplot at 0x7ffc8df80cd0>

In [14]:
# 결론적으로 LoanAmount, ApplicantIncome은 extreme values를 갖고 있기 때문에, data munging이 필요하다.
Categorical variable analysis
In [15]:
temp1 = df['Credit_History'].value_counts(ascending=True)
print 'Frequency Table for Credit History:'
print temp1
# Credit_History에 따른 Loan_Status의 mean값을 계산
temp2 = df.pivot_table(values='Loan_Status',index=['Credit_History'],aggfunc=lambda x: x.map({'Y':1,'N':0}).mean())
print '\nProbility of getting loan for each Credit History class:'
print temp2 Frequency Table for Credit History:
0.0 89
1.0 475
Name: Credit_History, dtype: int64
Probility of getting loan for each Credit History class:
Credit_History
0.0 0.078652
1.0 0.795789
Name: Loan_Status, dtype: float64In [16]:
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(8,4))
temp1.plot(kind='bar')
ax1 = fig.add_subplot(121)
ax1.set_xlabel('Credit_History')
ax1.set_ylabel('Count of Applicants')
ax1.set_title("Applicants by Credit_History")
temp2.plot(kind = 'bar')
ax2 = fig.add_subplot(122)
ax2.set_xlabel('Credit_History')
ax2.set_ylabel('Probability of getting loan')
ax2.set_title("Probability of getting loan by credit history")
# 결과적으로 8배의 credit_history가 이는 경우 더 많은 loan의 기회를 얻는다.Out[16]:
<matplotlib.text.Text at 0x7ffc8dcb2f10>

In [17]:
temp3 = pd.crosstab(df['Credit_History'], df['Loan_Status'])
print temp3
temp3.plot(kind='bar', stacked=True, color=['red','blue'], grid=True)Loan_Status N Y
Credit_History
0.0 82 7
1.0 97 378Out[17]:
<matplotlib.axes._subplots.AxesSubplot at 0x7ffc8df8b790>

Data Munging in Python: using Pandas
- There are missing values in some variables. We should estimate those values wisely depending on the amount of missing values and the expected importance of variables.
- While looking at the distributions, we saw that ApplicantIncome and LoanAmount seemed to contain extreme values at either end. Though they might make intuitive sense, but should be treated appropriately.
In [18]:
# Check missing values in the dataset null, Nan
df.apply(lambda x: sum(x.isnull()),axis=0) Out[18]:
Loan_ID 0
Gender 13
Married 3
Dependents 15
Education 0
Self_Employed 32
ApplicantIncome 0
CoapplicantIncome 0
LoanAmount 22
Loan_Amount_Term 14
Credit_History 50
Property_Area 0
Loan_Status 0
dtype: int64In [19]:
# How to fill missing values in LoanAmount
# numerical data는 simple하게 mean의 값으로 채워 넣는다.
df['LoanAmount'].fillna(df['LoanAmount'].mean(), inplace=True)
df['Self_Employed'].value_counts()Out[19]:
No 500
Yes 82
Name: Self_Employed, dtype: int64In [27]:
df['Self_Employed'].fillna('No',inplace=True)In [28]:
table = df.pivot_table(values='LoanAmount', index='Self_Employed' ,columns='Education', aggfunc=np.median)
# Define function to return value of this pivot_table
def fage(x):
return table.loc[x['Self_Employed'],x['Education']]
# Replace missing values
df['LoanAmount'].fillna(df[df['LoanAmount'].isnull()].apply(fage, axis=1), inplace=True)In [22]:
# How to treat for extreme values in distribution of LoanAmount and ApplicantIncome?In [29]:
# Histogram을 그려보면 실제로 extreme value가 있다.
# 그렇기 때문에 extrme value의 값들을 outliers로서 처리하기 전에 log transformation을 해주자. outliers의 영향력을 무효화 하기 위해
df['LoanAmount'].hist(bins=20)Out[29]:
<matplotlib.axes._subplots.AxesSubplot at 0x7ffc8d8c4490>

In [30]:
df['LoanAmount_log'] = np.log(df['LoanAmount'])
df['LoanAmount_log'].hist(bins=20)
# 결과적으로 분포가 normal에 많이 가까워졌다. extreme values의 영향이 상당히 완화가 되었다Out[30]:
<matplotlib.axes._subplots.AxesSubplot at 0x7ffc8d786d50>

In [151]:
# applicants가 낮은 income이 있지만 strong co-applicants가 있을 것이여? 두개를 하볓서 np.log transformation을 하자... 왜?ㅇ
# 위에서 ApplicantIncome과 CoapplicantIncome의 값의 분포가 extreme values 때문에 data muning이 필요했다.
df['TotalIncome'] = df['ApplicantIncome'] + df['CoapplicantIncome']
df['TotalIncome_log'] = np.log(df['TotalIncome'])
df['LoanAmount_log'].hist(bins=20) Out[151]:
<matplotlib.axes._subplots.AxesSubplot at 0x7fe3f72ee0d0>

Building a Predictive Model in Python
In [146]:
# 위 작업을 통해서 데이터를 modeling하기 좋게 형태를 만들었습니다. scikit=learn을 통해서 predictive model을 만들어보려고 합니다.
# scikitlearn은 numerical data만 허용하기 때문에 categorical variables을 numeric하게 변경을 해주어야 합니다.
from sklearn.preprocessing import LabelEncoder
var_mod = ['Gender','Married','Dependents','Education','Self_Employed','Property_Area','Loan_Status']
le = LabelEncoder()
for i in var_mod:
df[i] = le.fit_transform(df[i])
df.dtypes Out[146]:
Loan_ID object
Gender int64
Married int64
Dependents int64
Education int64
Self_Employed int64
ApplicantIncome int64
CoapplicantIncome float64
LoanAmount float64
Loan_Amount_Term float64
Credit_History float64
Property_Area int64
Loan_Status int64
dtype: objectIn [143]:
#Import models from scikit learn module:
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import KFold #For K-fold cross validation
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn import metrics
#Generic function for making a classification model and accessing performance:
def classification_model(model, data, predictors, outcome):
#Fit the model:
model.fit(data[predictors],data[outcome])
#Make predictions on training set:
predictions = model.predict(data[predictors])
#Print accuracy
accuracy = metrics.accuracy_score(predictions,data[outcome])
print "Accuracy : %s" % "{0:.3%}".format(accuracy)
#Perform k-fold cross-validation with 5 folds
kf = KFold(data.shape[0], n_folds=5)
error = []
for train, test in kf:
# Filter training data
train_predictors = (data[predictors].iloc[train,:])
# The target we're using to train the algorithm.
train_target = data[outcome].iloc[train]
# Training the algorithm using the predictors and target.
model.fit(train_predictors, train_target)
#Record error from each cross-validation run
error.append(model.score(data[predictors].iloc[test,:], data[outcome].iloc[test]))
print "Cross-Validation Score : %s" % "{0:.3%}".format(np.mean(error))
#Fit the model again so that it can be refered outside the function:
model.fit(data[predictors],data[outcome]) In [7]:
df['Credit_History'] = df['Credit_History'].fillna(1)
Logistic Regression
In [144]:
# 여기서 predictor_var의 값이 NaN이면 안되기 때문에 위에서 0으로 채움
outcome_var = 'Loan_Status'
model = LogisticRegression()
predictor_var = ['Credit_History']
classification_model(model, df,predictor_var,outcome_var)Accuracy : 80.945%
Cross-Validation Score : 80.946%In [147]:
#We can try different combination of variables:
predictor_var = ['Credit_History','Education','Married','Self_Employed','Property_Area']
classification_model(model, df,predictor_var,outcome_var)
# features을 추가하면 accuracy가 높아질것으로 예상을 했으나, 변화가 없었다.
# 그 말은 Credit_History가 다른 features에 비해 우세하다는 영향력이 더 의미 있다고 할 수 있다.Accuracy : 80.945%
Cross-Validation Score : 80.946%
Decision Tree
In [148]:
# 보통 Decision Tree는 logistic regression model보다 더 높은 accuracy를 갖는다고 알려져 있다.
model = DecisionTreeClassifier()
predictor_var = ['Credit_History','Gender','Married','Education']
classification_model(model, df,predictor_var,outcome_var)Accuracy : 80.945%
Cross-Validation Score : 80.946%In [152]:
# We can try different combination of variables:
# 위의 모든 data가 categorical variables이기 때문에 Credit_History보다 impact가 없다... 그래서 numerical variables로 변경하면
df['Loan_Amount_Term'].fillna(df['Loan_Amount_Term'].mean(), inplace=True)
predictor_var = ['Credit_History','Loan_Amount_Term','LoanAmount_log']
classification_model(model, df,predictor_var,outcome_var)
# 내용을 보면 accuracy는 올라갔지만, cross-validation score는 떨어진 것을 볼 수 있다. 즉 이 모델인 over-fitting됬다고 할 수 있다.Accuracy : 88.925%
Cross-Validation Score : 68.883%
Random Forest
In [153]:
# Random Forest의 장점은 featuer의 importances를 반환해준다는게 장점이다
model = RandomForestClassifier(n_estimators=100)
predictor_var = ['Gender', 'Married', 'Dependents', 'Education',
'Self_Employed', 'Loan_Amount_Term', 'Credit_History', 'Property_Area',
'LoanAmount_log', 'TotalIncome_log']
classification_model(model, df,predictor_var,outcome_var)
# Accuracy가 100%의 값이 나오는 것을 볼 수 있다. overffiting이 된건데, 해결하기 위한 방법은 아래와 같다.
# Reducing the number of predictors
# Tuning the model parametersAccuracy : 100.000%
Cross-Validation Score : 77.039%
In [154]:
#Create a series with feature importances:
featimp = pd.Series(model.feature_importances_, index=predictor_var).sort_values(ascending=False)
print featimpCredit_History 0.267269
TotalIncome_log 0.253663
LoanAmount_log 0.228351
Dependents 0.057279
Property_Area 0.051003
Loan_Amount_Term 0.043376
Gender 0.030116
Married 0.024297
Education 0.023163
Self_Employed 0.021481
dtype: float64In [156]:
model = RandomForestClassifier(n_estimators=25, min_samples_split=25, max_depth=7, max_features=1)
predictor_var = ['TotalIncome_log', 'LoanAmount_log','Credit_History','Dependents','Property_Area']
classification_model(model, df,predictor_var,outcome_var)
# Accuracy가 낮아진 것을 볼 수 있지만, cross-validation의 값이 증가한것을 알 수 있다.
# random forest는 값을 돌릴때마다 randomize때문에 다소 다른 값을 나타낸다. Accuracy : 82.085%
Cross-Validation Score : 80.622%
[참고]
http://datahack.analyticsvidhya.com/contest/practice-problem-loan-prediction-iii
http://www.analyticsvidhya.com/blog/2016/01/complete-tutorial-learn-data-science-python-scratch-2/
'Big Data > 데이터 분석' 카테고리의 다른 글
| [데이터 분석] Python 라이브러리 - Pandas, Matplotlib, Numpy 10분만에 배우기 (0) | 2021.05.03 |
|---|---|
| [데이터 분석] Data Exploration Guide - The Art of Feature Engineering(4) (0) | 2021.05.03 |
| [데이터 분석] Data Exploration Guide - Outlier(3) (0) | 2021.05.03 |
| [데이터 분석] Data Exploration Guide - Missing Value Treatment(2) (0) | 2021.05.03 |
| [데이터 분석] Data Exploration Guide - (1) (0) | 2021.05.03 |